
NER powered Semantic Search Engine
Published:
In this tutorial, we will demonstrate how to utilize Named Entity Recognition (NER) powered semantic search with Pinecone. The following steps will be covered:
- Identify named entities from the input text.
- Add the identified named entities as metadata to a Pinecone index alongside their respective text vectors.
- Extract named entities from incoming queries and use them to filter and search only through records that contain these named entities.
This technique can be advantageous if you want to limit the search results to records that contain information about the named entities found in the query.
Let’s begin.
Install Dependencies
## Uncomment to install required packages
# !pip install --upgrade tensorflow
# !pip install transformers
# !pip install sentence_transformers
# !pip install pinecone-client
# !pip install datasets
Load and Prepare Dataset
We will be working with a dataset that comprises approximately 190,000 articles scraped from Medium. As indexing all of the articles may be time-consuming, we will select 50,000 articles to work with. The dataset can be obtained from the HuggingFace dataset hub using the following method:
from datasets import load_dataset
# load the dataset and convert to pandas dataframe
data = load_dataset(
"fabiochiu/medium-articles",
data_files="medium_articles.csv",
split="train"
).to_pandas()
Found cached dataset csv (/home/fm-pc-lt-220/.cache/huggingface/datasets/fabiochiu___csv/fabiochiu--medium-articles-96791ff68926910d/0.0.0/6b34fb8fcf56f7c8ba51dc895bfa2bfbe43546f190a60fcf74bb5e8afdcc2317)
# drop empty rows and select 50k articles
df = data.dropna().sample(50000, random_state=2023)
df.head()
| title | text | url | authors | timestamp | tags | |
|---|---|---|---|---|---|---|
| 131521 | Credit Repair with Lanx Credit Solution | Ellie Jones told me about Lanx Credit Solution... | https://medium.com/@tk506667/credit-repair-wit... | ['Todd Knight'] | 2020-12-17 02:52:56.440000+00:00 | ['Covid 19', 'Covid 19 Update', 'Money', 'Home... |
| 184225 | [Lifehacking] Time. And How to use it well dur... | Lucius Seneca was a famous Roman statesman and... | https://medium.com/@djoann/lifehacking-time-an... | ['Djoann Fal'] | 2019-11-14 16:40:03.332000+00:00 | ['Life Lessons', 'Time', 'Lifehacks'] |
| 54358 | Binance Flash Update | Online activities\n\nZEN Competition — 10,000 ... | https://medium.com/binanceexchange/binance-fla... | [] | 2018-05-28 10:26:48.483000+00:00 | ['Binance', 'Blockchain', 'Cryptocurrency', 'B... |
| 37182 | Hugh Nibley — A Tentative Theology | Recently I read The Essential Nibley, an abrid... | https://medium.com/interfaith-now/hugh-nibley-... | ['Nathan Smith'] | 2020-03-16 17:00:06.866000+00:00 | ['Mormon', 'Theology', 'Mormonism', 'Religion'... |
| 72819 | Defi Exchange Injective Protocol Bringing Trad... | The decentralized exchange Injective Protocol ... | https://medium.com/the-capital/defi-exchange-i... | ['The Crypto Basic'] | 2021-01-02 13:49:00.687000+00:00 | ['Cryptocurrency', 'Cryptocurrency News', 'Def... |
## dump data to csv if you don't want to re-download it
# df.to_csv('medium.csv', index = False)
To generate embeddings, we will utilize the article title and its text. To do so, we will combine the article title with the first 500 characters of the article text.
df["title_text"] = df["title"] + ". " + df["text"].str[:500]
df = df.reset_index().rename(columns={'index': 'article_id'})
dfs = df.copy()
NER Model
To extract named entities, we will use a dslim/bert-base-NER model.
dslim/bert-base-NERrefers to a pre-trained language model that utilizes the Bidirectional Encoder Representations from Transformers (BERT) architecture for Named Entity Recognition (NER) tasks. It has been trained to recognize four types of entities: location (LOC), organizations (ORG), person (PER) and Miscellaneous (MISC). More here.
# https://huggingface.co/dslim/bert-large-NER
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
2023-03-11 16:55:39.394384: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F AVX512_VNNI FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-03-11 16:55:39.492583: I tensorflow/core/util/port.cc:104] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2023-03-11 16:55:40.132642: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory
2023-03-11 16:55:40.132786: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory
2023-03-11 16:55:40.132790: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
model_id = "dslim/bert-base-NER"
# load the tokenizer from huggingface
tokenizer = AutoTokenizer.from_pretrained(model_id)
# load the NER model from huggingface
model = AutoModelForTokenClassification.from_pretrained(model_id)
# load the tokenizer and model into a NER pipeline
nlp = pipeline(
"ner",
model=model,
tokenizer=tokenizer,
aggregation_strategy="max",
device= 0 # gpu
)
%%time
text = "My name is Kshitiz and I live in Kathmandu, Nepal."
# use the NER pipeline to extract named entities from the text
nlp(text)
CPU times: user 352 ms, sys: 144 ms, total: 497 ms
Wall time: 494 ms
[{'entity_group': 'PER',
'score': 0.99895954,
'word': 'Kshitiz',
'start': 11,
'end': 18},
{'entity_group': 'LOC',
'score': 0.9995191,
'word': 'Kathmandu',
'start': 33,
'end': 42},
{'entity_group': 'LOC',
'score': 0.99979967,
'word': 'Nepal',
'start': 44,
'end': 49}]
# Extract the named entities from the title_text column and lowercase all entities
title_text = dfs.title_text.values.tolist()
# Extract entity
from tqdm import tqdm
batch_size = 1000
last = len(title_text)
nlp_obj = list()
for i in tqdm(range(0,last, batch_size)):
start = i
end = i + batch_size
batch = title_text[start: end]
nlp_obj.append(nlp(batch))
100%|███████████████████████████████████████████| 50/50 [09:12<00:00, 11.05s/it]
nlp_obj[0][0]
[{'entity_group': 'MISC',
'score': 0.68047166,
'word': 'Lanx Credit Solution',
'start': 19,
'end': 39},
{'entity_group': 'PER',
'score': 0.9992043,
'word': 'Ellie Jones',
'start': 41,
'end': 52},
{'entity_group': 'MISC',
'score': 0.74122673,
'word': 'Lanx Credit Solution',
'start': 67,
'end': 87},
{'entity_group': 'ORG',
'score': 0.85671353,
'word': 'Fico',
'start': 125,
'end': 129}]
all_ner = [item for first_batch in nlp_obj for item in first_batch]
len(all_ner)
50000
# example
all_ner[0]
[{'entity_group': 'MISC',
'score': 0.68047166,
'word': 'Lanx Credit Solution',
'start': 19,
'end': 39},
{'entity_group': 'PER',
'score': 0.9992043,
'word': 'Ellie Jones',
'start': 41,
'end': 52},
{'entity_group': 'MISC',
'score': 0.74122673,
'word': 'Lanx Credit Solution',
'start': 67,
'end': 87},
{'entity_group': 'ORG',
'score': 0.85671353,
'word': 'Fico',
'start': 125,
'end': 129}]
# find words in entity
from tqdm import tqdm
ents = [[item.get('word') for item in doc] for doc in tqdm(all_ner)]
100%|████████████████████████████████| 50000/50000 [00:00<00:00, 1070363.24it/s]
# also concatinate tags, author name and extracted entity as one feature artilce_tags
# tokens = [list(map(str.lower, eval(a) + eval(t))) for a, t in zip(dfs.authors, dfs.tags)]
tokens = [eval(a) + eval(t) for a, t in zip(dfs.authors, dfs.tags)]
article_tags = [list(set(t + e)) for t, e in zip(tokens, ents)]
article_tags[0]
['Fico',
'Lanx Credit Solution',
'Money',
'Covid 19',
'Covid 19 Update',
'Ellie Jones',
'Homeless',
'Todd Knight']
eval(dfs.authors[0]) , eval(dfs.tags[0]), ents[0]
(['Todd Knight'],
['Covid 19', 'Covid 19 Update', 'Money', 'Homeless'],
['Lanx Credit Solution', 'Ellie Jones', 'Lanx Credit Solution', 'Fico'])
# Alternative way
# entities = dfs.title_text.apply(nlp)
# ents= list()
# for item in entities:
# ner = [d['word'] for d in item]
# ents.append(list(set(ner)))
# tokens = dfs.authors.apply(eval) + dfs.tags.apply(eval)
# tokens = tokens.apply(lambda word_list: [word.lower() for word in word_list]).tolist()
# article_tags = [list(set(t + e)) for t, e in zip(tokens, ents)]
dfs['named_entities'] = article_tags
Sentence transformer model to calculate embeddings
A sentence transformer model is a type of natural language processing model that uses deep learning techniques to convert sentences or text into high-dimensional vectors known as embeddings.
We will use a sentence-transformer model to compute embedding of the passages (article title + first 1500 characters) and queries. It creates embeddings such that queries and passages with similar meanings are close in the vector space as shown in following figure:
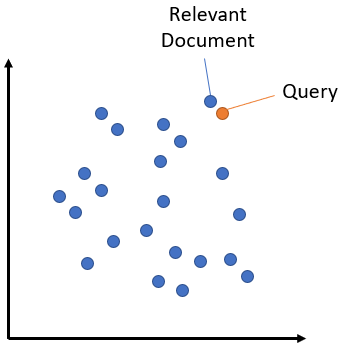
These embeddings capture the semantic meaning of the sentence and can be used for a wide range of downstream NLP tasks such as semantic search, sentiment analysis, text classification, question answering, and machine translation.
multi-qa-MiniLM-L6-cos-v1
This is a sentence-transformers model: It maps sentences & paragraphs to a 384 dimensional dense vector space and was designed for semantic search. It has been trained on 215M (question, answer) pairs from diverse sources. More here
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('multi-qa-MiniLM-L6-cos-v1')
dim = model.encode(['My name is Kshitiz and I live in Kathmandu, Nepal.']).shape[1]
dim
384
# compute embeddings for each title_text using sentence transformer model
encoded_titles = model.encode(dfs['title_text'].tolist(), show_progress_bar=True)
embeddings = encoded_titles.tolist()
Batches: 0%| | 0/1563 [00:00<?, ?it/s]
Pinecone
The Pinecone vector database makes it easy to build high-performance vector search applications.
Steps:
Setps:
- Initialize Pinecone connection
- Create index to store documents
- Store the vector representations of the passage and metadata on the index
- Use that index to retrieve similar documents based on meaning using another vector (the query vector).
For this, you need a free API Key. Sign Up to get started.
import pinecone
# connect to pinecone environment
pinecone.init(
api_key="70277004-4f22-44f7-81e0-c9a8ea54b1bb",
environment="us-east-1-aws" # find next to API key in console
)
Now we can create our vector index. We will name it ner-search (feel free to chose any name you prefer). We specify the metric type as cosine and dimension as 384 as these are the vector space and dimensionality of the vectors output by the retriever model.
index_name = "ner-filtered-semantic-search-index"
# check if the ner-search index exists
if index_name not in pinecone.list_indexes():
# create the index if it does not exist
pinecone.create_index(
index_name,
dimension=dim,
metric="cosine"
)
# connect to ner-search index we created
index = pinecone.Index(index_name)
# We have limited capacity to index data in free account therefore For now i will delete all metadata(demo only)
dfs.drop(columns=['title_text', 'text', 'timestamp', 'url', 'authors', 'tags'], inplace = True)
# Convert remaining metadata to dictionary
metadata = dfs.to_dict(orient='records')
# ids should be string type
ids = dfs.article_id.values.astype(str).tolist()
# add all to upsert list
to_upsert = list(zip(ids, embeddings, metadata))
# Insert data in batch due to size limitations
batch_size = 700
last = len(to_upsert)
for i in tqdm(range(0,last, batch_size)):
start = i
end = i + batch_size
batch = to_upsert[start: end]
_ = index.upsert(vectors=batch)
100%|███████████████████████████████████████████| 72/72 [09:08<00:00, 7.62s/it]
Inference Pipeline
import pinecone
# connect to pinecone environment
pinecone.init(
api_key="70277004-4f22-44f7-81e0-c9a8ea54b1bb",
environment="us-east-1-aws" # find next to API key in console
)
index_name = "ner-filtered-semantic-search-index"
# connect to ner-search index we created
index = pinecone.Index(index_name)
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
from sentence_transformers import SentenceTransformer
model_id = "dslim/bert-base-NER"
# load the tokenizer from huggingface
tokenizer = AutoTokenizer.from_pretrained(model_id)
# load the NER model from huggingface
nermodel = AutoModelForTokenClassification.from_pretrained(model_id)
# load the tokenizer and model into a NER pipeline
nlp = pipeline(
"ner",
model=nermodel,
tokenizer=tokenizer,
aggregation_strategy="max",
device= 0 # gpu
)
model = SentenceTransformer('multi-qa-MiniLM-L6-cos-v1')
def semantic_search_tag_powered(query):
# extract named entities from the query
ne= list()
nlpobj = nlp(query)
ne = [d['word'] for d in nlpobj]
xq = model.encode(query).tolist()
# query the pinecone index while applying named entity filter
xc = index.query(xq, top_k=15, include_metadata=True, filter={"named_entities": {"$in": ne}} )
# extract article titles from the search result
return {"NER": ne, "result": xc}
query = "Tech Billionaires Snipe at Each Other on Social Media"
res = semantic_search_tag_powered(query)
recommendations = [item.get('id') for item in res['result']['matches']]
import pandas as pd
inference_df = pd.read_csv('medium.csv')
recommended_articles = inference_df[inference_df["article_id"].astype(str).isin(recommendations)]
print(res['NER'])
rec_with_tags = recommended_articles.title.values
['Social', 'Media']
rec_with_tags
array(['Social Media Is Making Us Miserable: Here’s What You Can Do About It',
'Social Media on Identity Construction', 'SOCIAL MEDIA AUTOMATION',
'The Positive Power of Social Media Influencers in 2020',
'“I just stumbled across your profile and thought we should connect”',
'Impact of Social Media', 'NetBase Live 2016',
'Content Creators: Why Its Deadly to Build Your Business Just on Social Media',
'Navigating the Social Media Realm as Managers',
'The Social Media “Suck”', 'Social Media is Not “Social”',
'How to increase social media presence for the business?',
'Tech companies are media companies now and I have a question 🙋\u200d♀️',
'Is Identity Verification The Answer to Ending Spam and Fake News on Social Media?',
'Digital Marketing Is NOT Just “Social Media”'], dtype=object)
def semantic_search_only(query):
xq = model.encode(query).tolist()
# query the pinecone index while applying named entity filter
xc = index.query(xq, top_k=15)
# extract article titles from the search result
return {"result": xc}
query = "Tech Billionaires Snipe at Each Other on Social Media"
res_without_tags = semantic_search_only(query)
res_without_tags
{'result': {'matches': [{'id': '187628', 'score': 0.563622653, 'values': []},
{'id': '11066', 'score': 0.543600857, 'values': []},
{'id': '164370', 'score': 0.523814619, 'values': []},
{'id': '59663', 'score': 0.521868765, 'values': []},
{'id': '184123', 'score': 0.518765, 'values': []},
{'id': '15866', 'score': 0.518764, 'values': []},
{'id': '98732', 'score': 0.518073916, 'values': []},
{'id': '140309', 'score': 0.514822721, 'values': []},
{'id': '115983', 'score': 0.512871444, 'values': []},
{'id': '186198', 'score': 0.510965645, 'values': []},
{'id': '161911', 'score': 0.499721557, 'values': []},
{'id': '20669', 'score': 0.496962816, 'values': []},
{'id': '18573', 'score': 0.49243769, 'values': []},
{'id': '56517', 'score': 0.488476753, 'values': []},
{'id': '89153', 'score': 0.488474697, 'values': []}],
'namespace': ''}}
rec_without_tags = [item.get('id') for item in res_without_tags['result']['matches']]
rec_articles_without_tags = inference_df[inference_df["article_id"].astype(str).isin(rec_without_tags)]
rec_without_tags = rec_articles_without_tags.title.values
len(rec_with_tags)
15
len(rec_without_tags)
15
rec_with_tags == rec_without_tags
array([ True, False, False, False, True, False, False, False, False,
False, False, False, False, False, False])
rec_with_tags
array(['Social Media Is Making Us Miserable: Here’s What You Can Do About It',
'Social Media on Identity Construction', 'SOCIAL MEDIA AUTOMATION',
'The Positive Power of Social Media Influencers in 2020',
'“I just stumbled across your profile and thought we should connect”',
'Impact of Social Media', 'NetBase Live 2016',
'Content Creators: Why Its Deadly to Build Your Business Just on Social Media',
'Navigating the Social Media Realm as Managers',
'The Social Media “Suck”', 'Social Media is Not “Social”',
'How to increase social media presence for the business?',
'Tech companies are media companies now and I have a question 🙋\u200d♀️',
'Is Identity Verification The Answer to Ending Spam and Fake News on Social Media?',
'Digital Marketing Is NOT Just “Social Media”'], dtype=object)
rec_without_tags
array(['Social Media Is Making Us Miserable: Here’s What You Can Do About It',
'The Positive Power of Social Media Influencers in 2020',
'Cyberpunk 2020', 'Tech’s Term Sheets of Harassment',
'“I just stumbled across your profile and thought we should connect”',
'Scott Amyx On The Internet Of Things, Robotics And Human Currency',
'Fortune 500 Companies on Social Media in 2016 — Analysis',
'NetBase Live 2016',
'Fake conservative Twitter account: “Suze Michelini”',
'Social Media: An Impactful But Overlooked Tool For PR',
'The ONE thing you need to understand about social media',
'How will the Social Media impact 2022 and beyond',
'Social Media — A Vessel of Untruths',
'A Social Media Startup That Shares Ad Revenue',
'Tech companies are media companies now and I have a question 🙋\u200d♀️'],
dtype=object)